
Descriptive Statistics Tutorial
In this interactive Jupyter notebook you will learn the very basics of statistics. Through statistics you can make sense of data and in today’s world this is a good skill to have. You will learn basic statistics concepts like, population, sample, difference between correlation and causation, centrality measures, simple distribution types and much more. Interactive exercises spread throughout this notebook will allow you to learn interactively.
Note: If you are viewing this notebook on http://www.stefanfiott.com, this version is read-only, so you can follow along but will not be able to modify the Python code to experiment. If you would like to experiment with the code, something I encourage you to do, then you need to download the Juypter notebook from here.
This notebook is a summary of the content available in the free course provided by Udacity, Intro to Descriptive Statistics. It is meant to be used to quickly learn or refresh your memory about descriptive statistics. Furthermore, in this notebook we will use Python instead of a spreadsheet to visualise and experiment.
%matplotlib inline
import matplotlib.pyplot as plt
from IPython.display import Markdown, display
import numpy as np
from scipy import stats
import pandas as pd
import seaborn as sns
sns.set_style("darkgrid")
sns.set()
#----------------------------------------------------------------------\n",
# Function to generate markdown output\n",
# Ref: https://stackoverflow.com/a/32035217\n",
def printmd(string):
display(Markdown(string))
Introduction to Research Methods
Surveys
Why use surveys?
In most areas of research, getting information about the whole population of interest is not feasible. A solution is therefore to collect information, through the use of surveys, from a group of people.
What makes up a survey?
Surveys include a variety of questions, some of which require simple yes or no answers, entering a value or range, or selecting from a group of options, while others are more open ended and require a structured response. The open ended questions yield qualitative data, while the other type of questions produce quantitative data, for example, numerical values such as heights, or star ratings.
Is survey data reliable?
To ensure that the data collected through a survey will give us insight into the wider population, we must ensure that:
- We survey enough people to have a good sample size.
- The people we survey are mixed enough to be representative of the population being studied.
- Follow a sound methodology to ensure valid data is collected.
- Survey questions are clearly worded and unambiguous as much as possible to reduce biased answers.
Benefits of using surveys to conduct research
- Easy way to collect information on a population.
- Can be conducted remotely through mail.
- Relatively inexpensive to carry out, requiring mostly time to build survey and getting responses.
- If data from surveys are shared, anyone can analyse the survey results.
Drawbacks of surveys
- Survey responses might be untruthful.
- Survey responses might be biased.
- Survey questions might not be understood leading to incorrect responses, also known as response bias.
- Some survey questions might not be answered, perhaps because they are too personal or considered sensitive topics. This is called non-response bias.
Defining constructs
When conducting research we come up with hypotheses that we then need to validate with data, through experimentation or simple data collection. For example, to investigate a hypothesis about diabetes one could choose to measure certain physiological attributes such as blood glucose level or blood pressure. However, certain research questions are more tricky and in these cases we have attributes that cannot be directly measured, for example, happiness or intelligence. These attributes are called constructs and to assess them we need to do so indirectly by measuring other features that we identify as part of the operational definition.
An operational definition is thus a statement that defines a construct using measurable variables.
An example will help make this clearer. Say you want to investigate whether better memory leads to better exam results. Now, since memory cannot be measured directly, it is a construct, and so we have to specify an operational definition to clearly state what will be measured to represent memory, for instance, the longest sequence of numbers remembered or how many faces are successfully recognised out of a data set.
Defining constructs and how to measure them is not easy and there are multiple ways how to achieve this.
Choosing Survey Participants
For the survey to provide good data that allows us to estimate the population parameters accurately, the sample of people selected to participate in the survey must be representative of the population. This is best achieved using a random sample rather than a convenience sample.
In a random sample, each individual in the population being studied has the same chance of being picked to participate and their selection would in no way affect the chances of other individuals in the population being chosen to participate as well.
A random sample is thus less likely to be biased and more likely to be representative of the population.
Populations and Samples
In statistics, a population is all the things that we are investigating, be they people, animals, objects or events. Since it is not feasible to collect data about a whole population, a representative sample is generally used to estimate the population parameters.
Parameters vs Statistics
The properties of a population such as mean value, are know as population parameters, while the respective estimates computed from a sample are called sample statistics.
The mean of a population is represented by $\mu$ (read as mu) and the standard deviation by $\sigma$ (read as sigma), while the equivalent sample statistics are represented by $\bar x$ (read as x bar) and $s$.
Good estimates will be close to the population parameters, however they will never be 100% accurate. The difference between the population mean and the sample mean is called the sampling error.
\[\text{sampling error} = \mu - \bar x\]In the code below we generate 500 ages using a normal distribution with the mean age set to 45, and then uniformly sample 10, 100 and 200 ages from this population. The sampling error decreases the larger the sample size is. but you can see that even with a small sample size of 10, the mean estimate is quite close to the real population mean.
If you are using the notebook version, experiment by changing the population and sample sizes and notice the effect this has on the sampling error.
def sample_x(source, n_samples, verbose=True):
if verbose: print("Sampling {0}...".format(n_samples))
samples = np.random.choice(source, size=n_samples, replace=False)
if verbose: print(stats.describe(samples))
if verbose: print("Sampling error: {0:.2f}\n".format(np.mean(source) - np.mean(samples)))
return samples
mu, sigma, samples = 45, 10, 500
ages = np.random.normal(mu, sigma, samples)
print("Population of {0} ages:".format(samples))
print(stats.describe(ages))
print("\n")
samples_10 = sample_x(ages, 10)
samples_100 = sample_x(ages, 100)
samples_200 = sample_x(ages, 200)
Population of 500 ages:
DescribeResult(nobs=500, minmax=(15.85490164073757, 73.90742609693436), mean=45.137212601697215, variance=108.69361449135353, skewness=-0.041490955768216674, kurtosis=-0.09113257447242651)
Sampling 10...
DescribeResult(nobs=10, minmax=(19.88652070329676, 47.83786019784573), mean=38.212082024466625, variance=77.23850969501734, skewness=-0.6792470363977482, kurtosis=-0.1139810102463259)
Sampling error: 6.93
Sampling 100...
DescribeResult(nobs=100, minmax=(18.371951284850688, 71.15748590375759), mean=45.153545512640115, variance=124.89459273219009, skewness=-0.22022552182372038, kurtosis=-0.23533988367099568)
Sampling error: -0.02
Sampling 200...
DescribeResult(nobs=200, minmax=(20.09499575554826, 71.69633148515956), mean=45.23428894584381, variance=114.54056647513713, skewness=0.013903566671972296, kurtosis=-0.4458271551715467)
Sampling error: -0.10
Visualise Relationships
Our brains are more adept at processing visual information and so we find it much easier to see relationships graphically rather than by looking at a bunch of numbers. For example, ten people were asked how much they slept before a memory exam and the following where the results collected. Assume this was done as part of research into whether sleep has an effect on temporal memory.
sleep_vs_memory = pd.DataFrame({'Sleeping time (hours)' : pd.Series([7,8,6,5,6,7,6.5,8.5,6.5,7]),
'Temporal memory score' : pd.Series([86,70,56,56,70,80,72,91,81,86])})
sleep_vs_memory.head(n=10)
| Sleeping time (hours) | Temporal memory score | |
|---|---|---|
| 0 | 7.0 | 86 |
| 1 | 8.0 | 70 |
| 2 | 6.0 | 56 |
| 3 | 5.0 | 56 |
| 4 | 6.0 | 70 |
| 5 | 7.0 | 80 |
| 6 | 6.5 | 72 |
| 7 | 8.5 | 91 |
| 8 | 6.5 | 81 |
| 9 | 7.0 | 86 |
Even though the table contains only ten data points, it is not easy to reach a conclusion whether sleep affects temporal memory. However, if we plot these using a scatter plot, any correlation will become apparent instantly.
fig, ax = plt.subplots(1,1, figsize=(7,4))
ax = sns.regplot(x="Sleeping time (hours)", y="Temporal memory score", data=sleep_vs_memory)
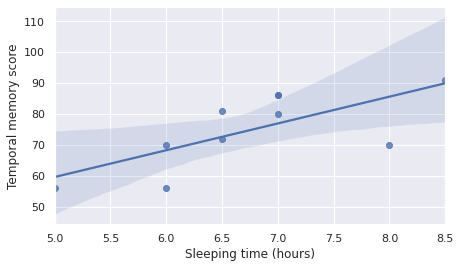
Note: The above plot also includes a fitted linear regression model with shaded confidence interval, clearly showing a postive correlation between the independent variable, sleeping time in hours, and the dependent variable, i.e. the temporal memory score.
It is evident from the scatter plot above, even without the fitted linear regression model line, that there seems to be a positive effect on temporal memory the longer one sleeps the night before the test. However, we need to be careful, since correlation does not imply causation.
Correlation vs Causation
This one is a tricky one and it trips a lot of people, even experienced ones. In the sleeping hours vs temporal memory score, the positive correlation shows that people who slept more the night before the temporal memory test achieved a better score. However, one cannot say that sleeping more improves memory. The positive correlation could be present due to some extraneous factor, such as hidden/latent/lurking variables, we do not know about yet or are not considering in the study. For instance, perhaps people who sleep more are more organised and so with better time management they find the time to sleep more. Them being organised might be because of other things and so it could be that either those other factors or their organisational skills helped them get a better memory score.
Figuring out causation, i.e. what really is affecting the outcome, is very hard, especially in studies involving many variables, for example, clinical studies.
How to show causation
As we have seen, determining causation is quite difficult. The only way to show causation is to conduct controlled experiments. As the name implies, in a controlled experiment the aim is to try and control as many of the variables that we know of and only influence one variable, say administering a drug. In this manner, if the outcome changes we can be sure that the variable we controlled is the causation.
Note: In clinical studies, to double-check and control the experiment, a double blind test is usually carried out. This means that, the patients in the experiment are randomly split into two groups, one group will be administered the experimental drug while the other group will be given a placebo. A placebo drug looks and weighs exactly the same as the real experimental drug, but is just sugar, for example, with no medicinal power. Furthermore, to make it double-blind, the people administering the drugs do not know which group of people is getting the experimental drug or not and have no idea whether the drug they are giving out is real or a placebo.
Surveys vs controlled experiments
In brief, surveys are used to collect quantitative and/or qualitative information, from which we can show relationships.
On the other hand, controlled experiments are used to show causation.
Types of variables
In the previous example, the number of hours slept, plotted on the x-axis, is called the independent variable or predictor variable, while the temporal memory score, plotted on the y-axis, is called the outcome or dependent variable.
Visualising Data
Frequency of Data
Often, when we collect a sample of data we would need to count how many responses we received for each particular category, if the data is categorical, or for each value, if the data is numerical. Different visualisations are used to represent the frequencies of data, depending on whether it is categorical (qualitative) or numerical (quantitative).
Categorical Data
Categorical data is qualitative data that falls into one out of a set of categories, for instance, eye colour or car brand. Categorical data is further divided into ordinal variables, i.e. those that can be ordered according to some rank, say grade, and nominal variables, i.e. those such as eye colour for which ranking does not make sense.
For categorical data, bar graphs with a bar for each possible value in the category are used.
Bar Graphs for Categorical Data
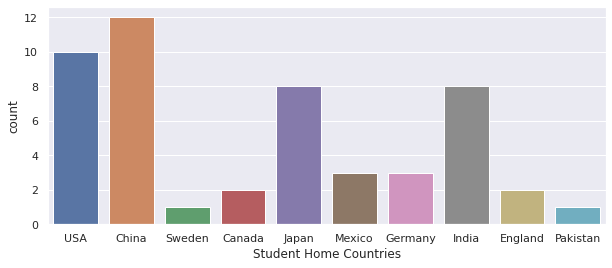
In this example, let us imagine we collected survey data from 50 students enrolled in a particular course, and one of the questions was about their home country, a nominal categorical variable. The code below will visualise this categorical variable using a bar graph to allow us to quickly figure out which home country is the commonest for our sample students. If the sample students were selected randomly and the sample is of sufficient size and representative, this should give us a clear idea about home countries for the wider student cohort, i.e. the student population.
student_home_countries = pd.Series(["USA","China","USA","Sweden","China",
"Canada","China","Japan","Mexico","USA",
"China","Germany","India","India","Japan",
"USA","USA","USA","China","China",
"India","Japan","England","India","Japan",
"England","India","China","Mexico","USA",
"Mexico","USA","Canada","Pakistan","India",
"Japan","China","USA","Japan","Germany",
"China","India","India","China","China",
"Germany","Japan","China","USA","Japan"],
name="Student Home Countries")
printmd("**Counts**")
print(student_home_countries.value_counts())
Counts
China 12
USA 10
India 8
Japan 8
Mexico 3
Germany 3
England 2
Canada 2
Sweden 1
Pakistan 1
Name: Student Home Countries, dtype: int64
fig, ax = plt.subplots(1, 1, figsize=(10,4))
sns.countplot(x=student_home_countries);
Relative Frequencies
Relative frequencies are computed by dividing each category count by the number of samples. So they range between 0 and 1, and sum up to 1. They can thus be used to represent the probability of each category.
print(student_home_countries.value_counts(normalize=True))
China 0.24
USA 0.20
India 0.16
Japan 0.16
Mexico 0.06
Germany 0.06
England 0.04
Canada 0.04
Sweden 0.02
Pakistan 0.02
Name: Student Home Countries, dtype: float64
Numerical Data
Numerical data is quantitative data such as age, height, income and so on. Numerical data can be split into discrete variables, i.e. variables that take values from a set of whole numbers, such as number of shirts bought, and continuous variables, i.e. variables that take values from a range of real values, such as height or temperature.
For numerical data histograms are used.
Histograms for Numerical Data
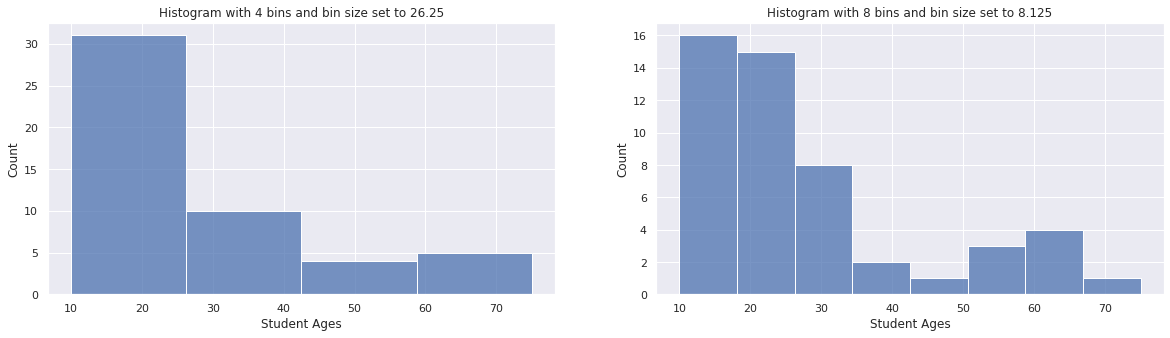
Let us now imagine that in the same survey given to 50 students we also asked them for their age. This is an example of discrete numerical data. Even though age is continuous numerical data we chose to accept only round figures, say 18 or 24. The following code will visualise the distribution of student ages using a histogram. We will also change the bin size to show how this affects the frequency counts.
student_ages = pd.Series([15,19,18,14,13,
27,16,65,15,31,
22,15,24,22,51,
24,20,45,22,33,
24,27,18,66,15,
18,39,10,30,13,
19,28,53,28,65,
30,20,21,20,18,
20,23,18,41,52,
75,19,63,14,18],
name="Student Ages")
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=[20,5])
sns.histplot(student_ages, bins=4, kde=False, ax=ax1)
ax1.set_title("Histogram with 4 bins and bin size set to 26.25")
sns.histplot(student_ages, bins=8, kde=False, ax=ax2)
ax2.set_title("Histogram with 8 bins and bin size set to 8.125");
If you are using the interactive notebook, you can drag the widget below to choose the number of bins and see how it affects the histogram.
from ipywidgets import widgets
def f(bins):
sns.histplot(student_ages, bins=bins, kde=False)
plt.show();
widgets.interact(f, bins=(1,10,1));
interactive(children=(IntSlider(value=5, description='bins', max=10, min=1), Output()), _dom_classes=('widget-…
Skewed Distributions
When counting frequencies it is quite common to have many data points for a certain range of values and much less for the rest of the values. When this happens we say the distribution is not symmetric but skewed. The data distribution can be either positively skewed or negatively skewed.
Positively Skewed Data
Positively skewed data, also known as skewed to the right data, is any data in which the distribution tails to the right of the highest frequency data point. For example, the majority of workers in a country, say 60% of all workers, might earn between \$20,000 and \$40,000 per year, while the remaining workers are spread out between \$40,001 and \$200,000, with only a few workers near the \$200,000 annual salary point.
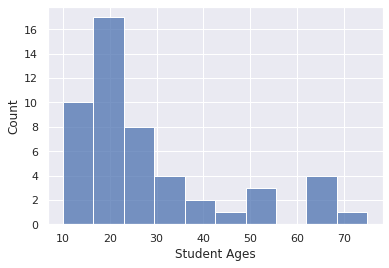
As can be seen below, the age distribution in the student sample we used before is an example of a positively skewed distribution, where the majority of students are younger than 30 years, and very few are older.
sns.histplot(student_ages, bins=10, kde=False);
Negatively Skewed Data
Negatively skewed data, also known as skewed to the left data, is any data in which the distribution tails to the left of the highest frequency data point. For example, if we ask a sample of 50 workers what is their average commute time and plot the distribution it will be negatively skewed, with the majority of sampled workers taking say more than 30 minutes to make it to work and the remaining minority taking less.
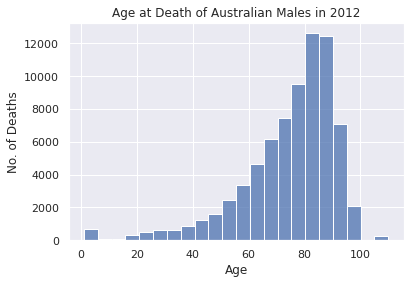
Another example of a negatively skewed data set would be the number of people who die in each age group in a specific year. Naturally, many more people die the older they become and so the distribution is skewed to the left, as can be seen below.
# Data for Age at Death of Australian Males in 2012. Ref: https://stats.stackexchange.com/a/122853
deaths_per_age = {1:565, 5:116, 10:69, 15:78, 20:319, 25:501, 30:633, 35:655, 40:848, 45:1226, 50:1633,
55:2459, 60:3375, 65:4669, 70:6152, 75:7436, 80:9526, 85:12619, 90:12455, 95:7113, 100:2104, 110:241}
sns.histplot(bins=len(list(deaths_per_age.keys())),
x=list(deaths_per_age.keys()),
weights=list(deaths_per_age.values()))
plt.title("Age at Death of Australian Males in 2012")
plt.ylabel("No. of Deaths")
plt.xlabel("Age");
Summarising a Distribution
To summarise a distribution, for example, the distribution of salaries for software engineers in a particular state or country, one can use any of the following statistical measures: mean, median or mode.
We will use the following small data set to show through code the practical meaning of mean, median and mode.
sample_distribution = pd.Series([4,7,2,9,8,3,5,12,8,7,3,5,6,1,7,2,11])
Mean
The sample mean, also commonly known as the average, is a sample statistic computed by summing up the values in the distribution and dividing by the number of samples present.
\[\bar x=\frac{\sum_{i=1}^nx_i}{n}\]Where $n$ is the number of samples and $x_i$ is the value of the $i^{th}$ sample, for example, a salary from a survey response.
If we had all the values for the whole population, we could compute the population mean, $\mu$, a population parameter, as follows.
\[\mu=\frac{\sum_{i=1}^Nx_i}{N}\]Where $N$ is the total number of items in the population and $x_i$ is the value of the $i^{th}$ population member.
printmd("**Mean: %.2f**" % (sample_distribution.mean()))
Mean: 5.88
Median
The median of a distribution can be found by sorting the values and choosing the middle one. If the number of samples in the distribution is even, the median would be the average (mean) of the two numbers in the middle of the sorted sequence.
printmd("**%d samples in distribution.**" % (sample_distribution.count()))
printmd("**Sorted distribution**")
sorted_sample_distribution = sample_distribution.sort_values()
print(sorted_sample_distribution.values)
printmd("**Median: %d**" % (sample_distribution.median()))
17 samples in distribution.
Sorted distribution
[ 1 2 2 3 3 4 5 5 6 7 7 7 8 8 9 11 12]
Median: 6
The way the median is computed makes it robust to outliers and is therefore a more appropriate centrality measure when dealing with highly skewed distributions. Let us look at a quick code example to notice how outliers would affect the mean drastically but only change the median slightly.
salary_list = [30000, 32000, 33500, 28000, 29500, 35000, 40000]
salary_distribution = pd.Series(salary_list)
printmd("**No outliers: mean = %d, median = %d**" % (salary_distribution.mean(), salary_distribution.median()))
# Add an outlier at 70000.
salary_list.append(70000)
salary_distribution = pd.Series(salary_list)
printmd("**One outlier of 70,000: mean = %d, median = %d**" % (salary_distribution.mean(), salary_distribution.median()))
No outliers: mean = 32571, median = 32000
One outlier of 70,000: mean = 37250, median = 32750
Mode
The mode is the value that occurs with the highest frequency in a distribution. In the sample distribution defined above, 7 is the most common number in the series and so the mode is 7.
printmd("**Mode: %d**" % (sample_distribution.mode()))
Mode: 7
sns.histplot(sample_distribution, bins=12, kde=False);
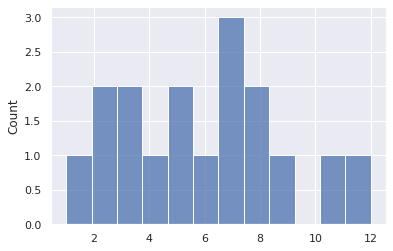
Relation of Mean, Median and Mode in Skewed Distributions
Normal Distribution
In a normal distribution, the data is spread out symmetrically around the centre, mean value of 0. The mean value is also the most frequent and so it follows that both mode and median will be equal to the mean.
Let us look at an example by drawing first a thousand random samples and then a million random samples from a standard normal distribution, i.e. a distribution having $\mu=0$ and $\sigma=1$, and then plotting the histograms for each to compare the mean, median and mode.
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=[20,5])
mu, sigma = 0, 1
sample_1k_normal_distribution = pd.Series(np.random.normal(mu, sigma, 1000))
sample_1M_normal_distribution = pd.Series(np.random.normal(mu, sigma, 1000000))
sns.histplot(sample_1k_normal_distribution, ax=ax1, kde=True);
sns.histplot(sample_1M_normal_distribution, ax=ax2, kde=True);
printmd("**1k samples : Mean = %.2f, Median = %.2f**" % (sample_1k_normal_distribution.mean(),
sample_1k_normal_distribution.median()))
ax1.set_title("Histogram for 1000 random samples from standard normal distribution")
printmd("**1M samples : Mean = %.2f, Median = %.2f**" % (sample_1M_normal_distribution.mean(),
sample_1M_normal_distribution.median()))
ax2.set_title("Histogram for 1000000 random samples from standard normal distribution");
1k samples : Mean = -0.00, Median = -0.01
1M samples : Mean = 0.00, Median = -0.00
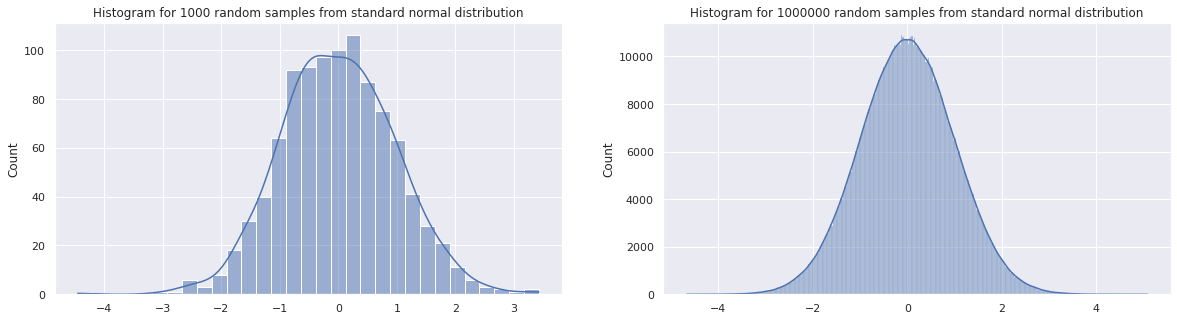
Notice how, the histogram for a million random samples, drawn on the right is more symmetric and closer to a proper standard normal distribution than the one drawn on the left, drawn using a thousand random samples. Since the mean, median and mode computed from the random samples are sample statistics, they estimate the actual standard normal distribution parameters.
Notice how the mean and median computed using a thousand samples are close to zero and do not match. However, the sample statistics computed using the million random samples match up and are equal to zero. This is because the more samples we have the closer the estimate gets to the real parameters.
Variability
The variability of a distribution is a measure that shows us how diverse the values sampled from a distribution will be. If a distribution has high variability, i.e. it has a wide spread, you may expect your samples to have quite different values, whereas if the distribution has a narrow spread, the majority of values will fluctuate around a specific value, most probably the mode value.
Let us look at a code example to generate two made up salary distributions, both based on a normal distribution, which however have very different variability.
small_spread_salaries = pd.Series(np.random.normal(50000, 10000, 200))
big_spread_salaries = pd.Series(np.random.normal(50000, 15000, 200))
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=[20,5])
sns.histplot(small_spread_salaries, kde=False, ax=ax1)
ax1.set_title("Small Spread Salaries")
ax1.set_xlim(0, 100000)
sns.histplot(big_spread_salaries, kde=False, ax=ax2)
ax2.set_title("Big Spread Salaries")
ax2.set_xlim(0, 100000);
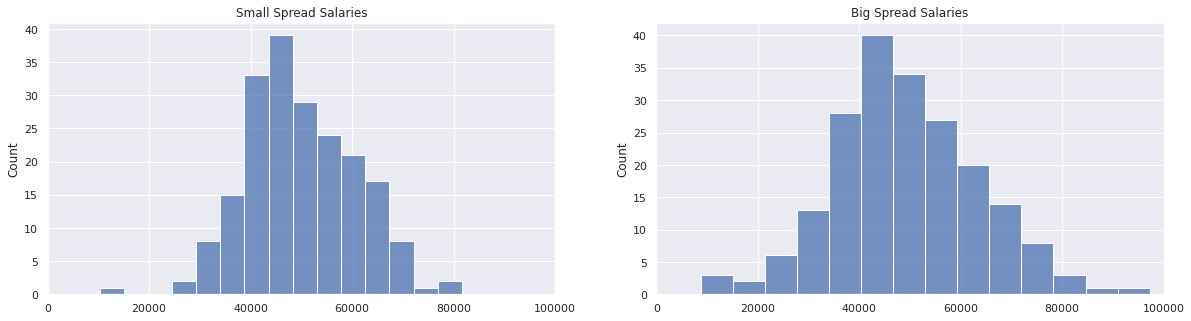
Both salary distributions have a mean salary of \$50000, however the salary distribution on the right is more spread out than the one on the left. We can quantify this by determining the minimum and maximum salaries sampled from each distribution and computing the range as follows.
\[range = value_{max} - value_{min}\]small_spread_range = small_spread_salaries.max() - small_spread_salaries.min()
big_spread_range = big_spread_salaries.max() - big_spread_salaries.min()
printmd("**Small spread salary distribution:**")
printmd("Min value = \\\\$%d, Max value = \\\\$%d, Range = \\\\$%d" % \
(small_spread_salaries.min(), small_spread_salaries.max(), small_spread_range))
printmd("**Big spread salary distribution:**")
printmd("Min value = \\\\$%d, Max value = \\\\$%d, Range = \\\\$%d" % \
(big_spread_salaries.min(), big_spread_salaries.max(), big_spread_range))
Small spread salary distribution:
Min value = \$10223, Max value = \$81641, Range = \$71418
Big spread salary distribution:
Min value = \$8691, Max value = \$97236, Range = \$88545
The range of a distribution changes only if new values that are either smaller than the existing minimum or larger than the existing maximum are added. The range metric is therefore very susceptible to outliers, i.e. extreme values. For instance, if in the small spread salary distribution we introduced a salary of \$100,000, the range would become:
printmd("**Small spread salary distribution range with \\\\$100,000 outlier: \\\\$%d**" % (100000 - small_spread_salaries.min()))
Small spread salary distribution range with \$100,000 outlier: \$89776
Therefore, range might not accurately represent the variability of data, especially if there are outliers.
Interquartile Range (IQR)
Quartiles, as the name implies, split a distribution into four groups. Always starting from the minimum value, Q1 includes the first 25% of the data, Q2 the first 50% of the data, and Q3 the first 75% of the data.
With this in mind, the IQR represents 50% of the data centred around the median, 25% on each side. So the IQR starts at the Q1 point and ends at the Q3 point.
Boxplots help us visualise quartiles clearly and make it possible to statistically determine outliers as follows.
A data point is an outlier if it satisfies either one of these rules:
\(value < Q1 - (1.5 \times IQR)\) \(value > Q3 + (1.5 \times IQR)\)
Box Plot
As mentioned, box plots are a great way to summarise visually the variability or spread of a data set. Let us generate box plots for each of the sample salary data sets we generated previously.
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=[20,5])
sns.boxplot(x=small_spread_salaries, ax=ax1)
ax1.set_title("Small Spread Salaries")
ax1.set_xlim(0, 100000)
sns.boxplot(x=big_spread_salaries, ax=ax2)
ax2.set_title("Big Spread Salaries")
ax2.set_xlim(0, 100000);
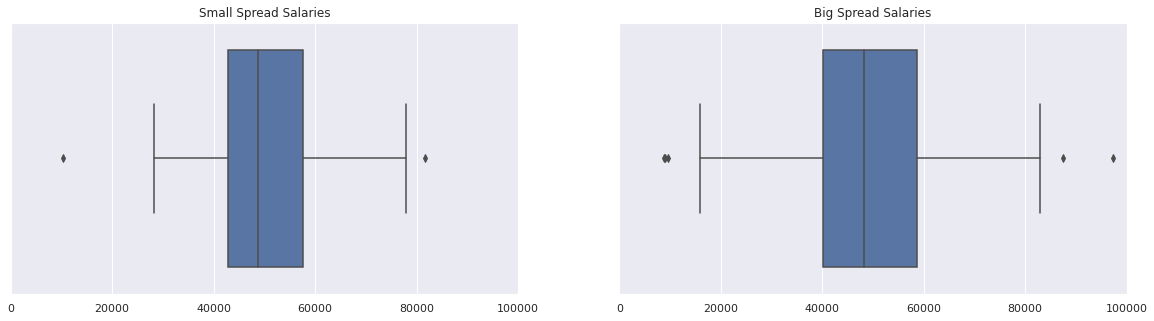
Starting from the blue box in the middle, the left side is Q1, the right side is Q3 and the line in the middle of the box represents Q2, the median. The blue box is therefore the IQR, (Q3 - Q1). The vertical lines outside the box are called whiskers and these represent the minimum and maximum values beyond which a data point would be considered an outlier. Outlier points would be plotted individually.
From the above plots it is quite clear that the data set on the right has a larger variability since the blue box is much wider. This is also reflected in the fact that the whiskers are set much farther apart.
Note: When comparing visual plots always ensure you are comparing like with like, so always double-check that the axes ranges are equal between the plots you are comparing.
Variance
Although quartiles and box plots give a good idea of variability, they do not summarise it perfectly. In fact, multiple distributions can have a very similar looking box plot.
A better statistical measure of variability is the variance which is computed by taking the difference between each data point and the mean value, squaring them up and summing them. The total sum is then divided by the number of data points. Mathematically the variance is represented by $\sigma_2$ and is computed using the following formula.
\[\sigma^2=\frac{\sum_{i=1}^{n}(x_i - \bar x)^2}{n}\]Standard Deviation
When we computed the variance, we found the average squared difference between data points and the mean. Therefore, to get a better idea of the data variability, we need to take the square root of the variance to get a mean difference. This is called the standard deviation, $\sigma$, and is the most common measure of data variability.
Let us look at an example using ten salaries to compute and better understand variance and standard deviation.
salaries_people_on_social_network = np.array([38946, 43420, 49191, 50430, 50557, 52580, 53595, 54135, 60181, 62076])
mean_salary_for_people_on_social_network = salaries_people_on_social_network.mean()
printmd("**Mean salary for people on social network: \\\\$%d**" % (mean_salary_for_people_on_social_network))
variance_computations = [((x - mean_salary_for_people_on_social_network)**2) for x in salaries_people_on_social_network]
printmd("**Squared differences:**")
print(variance_computations)
printmd("**Sum of squared differences = %.2f**" % (np.sum(variance_computations)))
variance = np.sum(variance_computations) / len(variance_computations)
printmd("**Variance = %.2f**" % (variance))
printmd("**Standard Deviation = \\\\$%.2f**" % (np.sqrt(variance)))
Mean salary for people on social network: \$51511
Squared differences:
[157881738.00999996, 65465899.20999998, 5382864.009999993, 1168777.209999997, 910306.8099999973, 1142547.2100000032, 4342639.2100000065, 6884851.210000007, 75167166.01000002, 111617112.01000004]
Sum of squared differences = 429963900.90
Variance = 42996390.09
Standard Deviation = \$6557.16
Above, we broke the computations required to compute the variance and standard deviation into individual steps to make the process more clear. However, in practice we would use the built-in functions to compute the above in one step as follows.
# Set degrees of freedom to 0, so as to divide by n instead of (n-1), and so match previous computation.
printmd("**Standard Deviation = \\\\$%.2f**" % (pd.Series(salaries_people_on_social_network).std(ddof=0)))
Standard Deviation = \$6557.16
100 Salaries Example
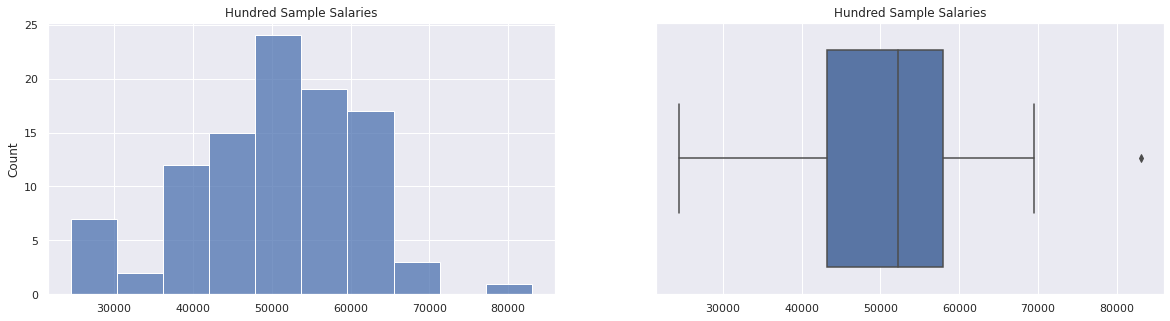
Let us use a data set made up of 100 sample salaries to summarise what we have learnt so far by plotting a histogram and box plot of the data set, calculating the mean salary, variance and standard deviation.
hundred_salaries = pd.Series([59147.29,61379.14,55683.19,56272.76,52055.88,47696.74,60577.53,49793.44,35562.29,58586.76,
47091.37,36906.96,53479.66,67834.74,53018.8,60375.11,36566.91,52905.58,51063.31,65431.26,
57071.83,30060.59,42619.62,52984.77,57871.28,41274.37,24497.78,47939.82,42755.52,57189.35,
37216.45,44742.99,47119.04,59269.48,53336.8,39719.54,69473.2,39831.55,58300.7,41726.66,
40283.35,59652.4,40326.61,28167.31,51420.36,55294.22,48116.14,36780.47,53628.89,48782.09,
33615.77,41881.34,64745.33,53482.58,48838.54,57031.73,62821.03,60627.78,46568.52,38977.05,
43250.62,67502.5,54696.18,43003.14,29156.83,61230.07,56749.93,48373.77,52428.26,29961.91,
54524.28,83017.28,49290.55,56375.66,64032.27,52947.6,61210.22,54438.94,48825.68,54118.71,
45305.73,42361.59,52852.52,62933.52,64330.23,48922.74,27211.96,62409.65,28981.92,64913.67,
55766,50748.04,43990.34,61828.33,45434.02,45369.16,54710.71,62222.43,44764.32,50973.48])
printmd("**Mean salary = \\\\$%.2f**" % (hundred_salaries.mean()))
printmd("**Variance = %.2f**" % (hundred_salaries.var()))
printmd("**Standard deviation = \\\\$%.2f**" % (hundred_salaries.std(ddof=0)))
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=[20,5])
sns.histplot(hundred_salaries, kde=False, ax=ax1)
ax1.set_title("Hundred Sample Salaries")
sns.boxplot(x=hundred_salaries, ax=ax2)
ax2.set_title("Hundred Sample Salaries");
Mean salary = \$50586.36
Variance = 114717818.36
Standard deviation = \$10656.95
Usefulness of Standard Deviation
Using standard deviations on a standard normal distribution, where the mean equals the median and mode, we can accurately estimate how many data points fall within a certain range of values.

Source: https://upload.wikimedia.org/wikipedia/commons/8/8c/Standard_deviation_diagram.svg
For example, from the above chart we can see that 68.2% of all data will fall within the mean minus one standard deviation and the mean plus one standard deviation. Mathematically, this is expressed as $\mu \pm \sigma$. Within the $\mu \pm 2\sigma$ we find 95.4% of data and within $\mu \pm 3\sigma$ we find 99.6% of all data. This is known as the 68-95-99.7 rule.
Bessel’s Correction
So far we have calculated the variance and standard deviation of a data set using the following formulas, in which we divide by $n$, the number of data points in the data set.
\[\sigma^2=\frac{\sum_{i=1}^{n}(x_i - \bar x)^2}{n}\] \[\sigma=\sqrt{\frac{\sum_{i=1}^{n}(x_i - \bar x)^2}{n}}\]However, if we are trying to estimate the variance and standard deviation of a population by using a sample of data points, we need to make a minor adjustment to the denominator $n$, called Bessel’s correction, since the estimates, sample statistics, will be generally smaller than the actual population parameter. The reason for this is that samples tend to be drawn from around the mean and so are less representative of the variability in the population. Bessel’s correction makes the estimates more accurate by subtracting 1 from the denominator $n$ in both variance and standard deviation calculations, as follows.
\[s^2=\frac{\sum_{i=1}^{n}(x_i - \bar x)^2}{n-1}\] \[s=\sqrt{\frac{\sum_{i=1}^{n}(x_i - \bar x)^2}{n-1}}\]Note that instead of $\sigma$, which stands for the population standard deviation, we are now using $s$ to represent the sample standard deviation.
Bessel’s Correction Example
In this code example, we will sample 100 numbers from a normal distribution with $\mu=40$ and $\sigma=5$ to represent our population. We then sample 10 numbers without replacement from this population and compare the results of estimating the standard deviation of the population with or without Bessel’s correction.
mu, sigma = 40, 5
hundred_population = np.random.normal(mu, sigma, 100)
sample_of_ten = np.random.choice(hundred_population, 10, replace=False)
printmd("**Standard deviation without Bessel's correction = %.2f, difference from sigma = %.2f**" % (sample_of_ten.std(ddof=0),
sample_of_ten.std(ddof=0) - sigma))
printmd("**Sample standard deviation (using Bessel's correction) s = %.2f, difference from sigma = %.2f**" % (sample_of_ten.std(ddof=1),
sample_of_ten.std(ddof=1) - sigma))
Standard deviation without Bessel’s correction = 3.55, difference from sigma = -1.45
Sample standard deviation (using Bessel’s correction) s = 3.75, difference from sigma = -1.25
Standardising, Z Scores and Tables
We now know how to visualise a normal distribution and also summarise it through the parameters $\mu$ for mean and $\sigma$ for standard deviation. Using both parameters we can calculate how many standard deviations away from the mean a data point is on the standard normal distribution. This value is called the Z score and is found using the following equation.
\[Z = \frac{x - \mu}{\sigma}\]If we processed all of the values in a data set using the above equation, we would end up with the standard normal distribution, which has $\mu=0$ and $\sigma=1$. From the Z score equation we can see why this is the case.
First, we are subtracting the mean of the data set from each value, thus the mean is shifted to zero in the new distribution.
Let $x = \mu$, then $Z = \frac{x - \mu}{\sigma} = \frac{\mu - \mu}{\sigma} = \frac{0}{\sigma} = 0$.
As regards the standard deviation, this is equal to one in the new distribution since we are dividing by $\sigma$.
Let $x = \mu + \sigma$, then $Z = \frac{x - \mu}{\sigma} = \frac{\mu + \sigma - \mu}{\sigma} = \frac{\sigma}{\sigma} = 1$
Let us look at a code example to see this standardising process in practice and plot both the original data distribution and the resulting standard normal distribution. In this example, we will be using the hundred_salaries distribution we previously used.
sns.histplot(hundred_salaries, kde=False).set_title("Hundred Salaries Distribution");
mu = hundred_salaries.mean()
sigma = hundred_salaries.std(ddof=0)
standardised_hundred_salaries = pd.Series([(x - mu)/sigma for x in hundred_salaries])
sns.histplot(standardised_hundred_salaries, kde=False).set_title("Standardised Hundred Salaries Distribution");
Using Z Scores and Z Tables
Z scores are pretty useful. Here we explore some common use cases, but before we do that we need to talk about continuous distributions. So far, we have always looked at discrete distributions and visualised them using histograms. In a histogram, the bin size or width affects the shape of the histogram. The larger the bin size the less detail about the underlying distribution we keep. On the other hand if the bin size is made too small, there is too much detail and we still lose sight of the actual distribution of data. Take a look at the following histograms for the same hundred_salaries distribution, increasing the bin size from left to right.
fig, (ax1, ax2, ax3, ax4, ax5) = plt.subplots(1, 5, figsize=[20, 5])
sns.histplot(hundred_salaries, bins=30, kde=False, ax=ax1).set_title("30 bins")
sns.histplot(hundred_salaries, bins=20, kde=False, ax=ax2).set_title("20 bins")
sns.histplot(hundred_salaries, bins=10, kde=False, ax=ax3).set_title("10 bins")
sns.histplot(hundred_salaries, bins=5, kde=False, ax=ax4).set_title("5 bins")
sns.histplot(hundred_salaries, bins=2, kde=False, ax=ax5).set_title("2 bins");
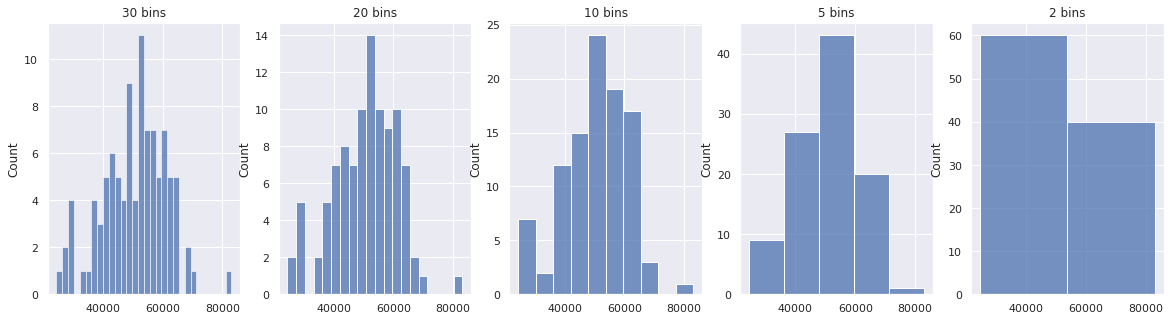
Furthermore, the bin size restricts us to computing relative likelihood for a specific range that matches with the bin sizes. If we need to compute a relative likelihood for a range that does not match up with the bin borders, we are out of luck.
Continuous distributions solve this issue by defining a distribution equation that in turn allows us to compute relative likelihoods using infinitesimally small bin sizes, through the use of integration. In this notebook we will not go into this any further, but for anyone interested in learning more you can start by reading about the normal distribution and the Gaussian probability density function here.
Luckily for us, based on the standard normal distribution, a table, named a Z table, was computed that allows us to read off the relative likelihood by looking up Z scores. We will look into how the Z table is used in one of the use cases below.
Determine Likelihood of a Value
Z scores make it possible to figure out whether a value is an exceptional occurrence, meaning it occurs with very low probability. For example, imagine a worker earns \$65000 annually and the mean annual salary in this example population is \$50000. Is this worker’s salary exceptional? It is hard to say without also knowing the standard deviation. If the standard deviation is \$5000 that salary would be exceptional, however, if standard deviation is \$20000, then \$65000 would be quite normal. The Z score combines both mean and standard deviation into a single metric that makes it clear if a data point is rare or not. The further the Z score is from zero, both positive or negative, the less likely is the event. In our previous example, the Z scores for the different standard deviations would be the following, respectively.
\[Z = \frac{x - \mu}{\sigma} = \frac{65000 - 50000}{5000} = 3\] \[Z = \frac{x - \mu}{\sigma} = \frac{65000 - 50000}{20000} = 0.75\]Compare Values From Different Normal Distributions
Z scores can be used to standardise normal distributions onto the standard normal distribution. This allows us to meaningfully compare the likelihood of values from different distributions. For example, Jack has 54 Twitter followers and the Twitter population parameters are $\mu = 208$ and $\sigma = 60$. Susan has 63 Facebook friends and the Facebook population parameters are $\mu = 190$ and $\sigma = 36$. Who is the least popular of the two? Assume that the operational definition of the popularity construct is the number of followers or friends. At first glance, one might say Jack is the least popular of the two, 54 followers to Susan’s 63 Facebook friends. However, to make the comparison meaningful we have to standardise both distributions to compare their respective Z scores. Doing this we find the following:
\[Z_{Jack} = \frac{x - \mu}{\sigma} = \frac{54 - 208}{60} = -2.5667\] \[Z_{Susan} = \frac{x - \mu}{\sigma} = \frac{63 - 190}{36} = -3.5278\]It now becomes clear that Susan is less popular than Jack. Her Z score is farther away from zero than Jack’s, which means that on the Facebook platform having such a low number of friends as Susan’s is highly unlikely, more than for Jack to have 54 followers on Twitter.
Determine Percent of Values Less Than or Greater Than a Value
When we convert a value to a Z score, we can look it up in a Z table to determine the percentage of the population that has a value smaller or bigger than the value we are investigating. For example, if a chess player has a rating of 1800, can we determine how many ranked players have a smaller rating or a larger rating? If we have the population parameters $\mu$ an $\sigma$, then yes. Let us say that $\mu=1200$ and $\sigma=240$. In this instance, $Z = \frac{x - \mu}{\sigma} = \frac{1800 - 1200}{240} = 2.5$. If we lookup $2.5$ in a Z table showing values for the area under the standard normal curve to the left of Z, we find out the value $0.9938$, which means that 99.38% of all ranked chess players have a lower rating than this example player.
Similarly, the complement, i.e. $1 - 0.9938 = 0.0062$, means that 0.62% of ranked chess players have a rating higher than 1800.
The Z score and table can also be used to find out the percentage of values in a distribution that fall within a particular range. To do so, we need to compute the Z score for the starting and ending value of the range, look them up in the Z table and subtract the ending Z score from the starting Z score. For example, what is the percentage of chess players that have a rating between 960 and 1440, i.e. $\mu \pm \sigma$.
First compute Z score for upper value, as follows, $Z_{max} = \frac{1440 - 1200}{240} = 1$, then compute Z score for the lower value, like so, $Z_{min} = \frac{960 - 1200}{240} = -1$.
Looking up the Z scores in a Z table we find $0.8413$ and $0.1587$ respectively. Subtracting gives us $0.6826$, i.e. 68.26% of players have a rating between 960 and 1440, as we would expect according to the 68-95-99.7 rule we previously mentioned.
Convert a Value from One Distribution to Another
Using the Z score equation we can convert a value from one distribution into an equivalent value from another distribution that satisfies certain parameters we want. An example will make this clear. Imagine that we would like to rank athletes from different disciplines on a common ten-point scale. Now, each discipline has its own ranking methodology and score that is standardised. How would it be possible to convert all these scores onto one ten-point scale fairly.
Using Z scores this is easy. Say athlete A has 274 points and parameters for this discipline are $\mu = 150$ and $\sigma = 50$. Athlete B has 958 points and parameters for this discipline are $\mu = 800$ and $\sigma = 100$. To score both athletes on a ten-point scale we need to do the following:
First, compute the Z scores for each athlete as follows:
\[Z_{A} = \frac{274-150}{50} = 2.48\] \[Z_{B} = \frac{958-800}{100} = 1.58\]Finally, use the desired parameters for the ten-point scale distribution, say $\mu = 5$ and $\sigma = 2$, along with the Z scores to compute the equivalent value in this new distribution by making $x$ the subject of the formula as follows.
\(Z = \frac{x - \mu}{\sigma}\) \(x = (Z \times \sigma) + \mu\)
This gives the following score to athlete A and B on the new ten-point scale.
\[x_{A} = (2.48 \times 2) + 5 = 9.96\] \[x_{A} = (1.58 \times 2) + 5 = 8.16\]Sampling Distributions
In this last section, we will now learn about one of the most important theorems in probability, the central limit theorem.
Informally, the central limit theorem states that no matter the type of distribution a population has, whether it is uniform, bimodal, skewed, normal and so on, if we take a sample of size $n$ from that population and compute the sample mean, and repeat this process over and over again, the distribution of sample means will be a normal distribution. The more sample means are included, the more the distribution converges towards a normal distribution.
So in brief, the central limit theorem states that:
- The distribution of sample means is approximately normal.
- The mean of the sample means is equal to the mean of the underlying population, $\mu$, and is known as the expected value $ (\mathbf) $.
- The standard deviation of the sample means is $\approx \frac{\sigma}{\sqrt{n}}$ where $n$ is the sample size. This is known as the standard error $ (SE) $.
Let us look at a code example to see the above in practice.
Facebook Friends - Positively Skewed Distribution Example
In this example we will show how a positively skewed data set will still produce a distribution of sample means that is approximately normal, as expected according to the central limit theorem.
Note: We will treat the Facebook friends data set as though it is a population and not a sample.
facebook_friends = pd.Series([372,0,51,116,0,40,50,201,56,185,150,288,224,381,40,465,258,27,0,331,605,295,
0,346,282,124,18,110,60,634,120,115,0,0,0,0,0,0,500,139,0,420,270,254,362,209,
178,70,345,212,406,123,0,513,0,517,14,40,305,0,0,206,0,60,6,250,200,200,40,0,
0,0,0,437,308,0,0,932,0,643,1014,101,80,300,735,103,103,220,25,0,0,779,0,0,634,
157,259,0,0,780,0,0,0,0,656,550,821,246,0,0,181,575,203,0,381,0,0,0,0,303,386,0,
465,150,208,102,0,100,0,275,1109,182,120,283,1000,637,134,500,0,446,463,50,296,
10,298,486,0,836,136,136,0,0,0,0,0,0,830,40,290,488,643,298,182,-1,206,345,108,
40,601,331,123,0,30,72,200,116,369,0,55,200,200,184,114,0,18,1,440,40,0,0,0,345,
400,150,420,500,345,106,531,406,72,213,213,4,125,643,0,0,432,0,0,0,185])
printmd("**Facebook friends population parameters: $\mu =$ %.2f, $\sigma = $ %.2f**" % (facebook_friends.mean(),
facebook_friends.std(ddof=0)))
def generate_sample_means(population, samples, sample_size):
sample_means = []
for _ in range(samples):
samples = np.random.choice(population, size=sample_size)
sample_means.append(samples.mean())
return pd.Series(sample_means)
sample_means_200_5 = generate_sample_means(facebook_friends, 200, 5)
sample_means_200_25 = generate_sample_means(facebook_friends, 200, 25)
sample_means_200_50 = generate_sample_means(facebook_friends, 200, 50)
printmd("**Sample means distributions**")
printmd("**200 samples, $n = 5$**")
printmd("Theoretical: $\mathbf = {0:.2f}$ , $SE = \\frac}} = \\frac}}} = {2:.2f}$".format(
facebook_friends.mean(), facebook_friends.std(ddof=0), facebook_friends.std(ddof=0)/np.sqrt(5)))
printmd("In practice: $\mathbf = {0:.2f}$ , $SE = {1:.2f}$".format(sample_means_200_5.mean(), sample_means_200_5.std()))
printmd("**200 samples, $n = 25$**")
printmd("Theoretical: $\mathbf = {0:.2f}$ , $SE = \\frac}} = \\frac}}} = {2:.2f}$".format(
facebook_friends.mean(), facebook_friends.std(ddof=0), facebook_friends.std(ddof=0)/np.sqrt(25)))
printmd("In practice: $\mathbf = {0:.2f}$ , $SE = {1:.2f}$".format(sample_means_200_25.mean(), sample_means_200_25.std()))
printmd("**200 samples, $n = 50$**")
printmd("Theoretical: $\mathbf = {0:.2f}$ , $SE = \\frac}} = \\frac}}} = {2:.2f}$".format(
facebook_friends.mean(), facebook_friends.std(ddof=0), facebook_friends.std(ddof=0)/np.sqrt(50)))
printmd("In practice: $\mathbf = {0:.2f}$ , $SE = {1:.2f}$".format(sample_means_200_50.mean(), sample_means_200_50.std()))
fig, (ax1, ax2, ax3, ax4) = plt.subplots(1, 4, figsize=[20,5])
ax1.set_xlim(0, 1000)
ax2.set_xlim(0, 600)
ax3.set_xlim(0, 600)
ax4.set_xlim(0, 600)
sns.histplot(facebook_friends, ax=ax1).set_title("Facebook Friends Population")
ax1.axvline(facebook_friends.mean(), linestyle="--", color="g")
ax1.text(facebook_friends.mean() + 10, 0.003, "$\mu=%.2f$" % (facebook_friends.mean()), fontsize=12, rotation=90, color="g")
sns.histplot(sample_means_200_5, ax=ax2, color="c").set_title("Sample Means Distribution: 200 samples, $n = 5$")
ax2.axvline(facebook_friends.mean(), linestyle="--", color="g")
ax2.axvline(sample_means_200_5.mean(), linestyle="--", color="w")
ax2.text(sample_means_200_5.mean() + 10, 0.001, "$\mu=%.2f$" % (sample_means_200_5.mean()), fontsize=12, rotation=90, color="c")
sns.histplot(sample_means_200_25, ax=ax3, color="m").set_title("Sample Means Distribution: 200 samples, $n = 25$")
ax3.axvline(facebook_friends.mean(), linestyle="-.", color="g")
ax3.axvline(sample_means_200_25.mean(), linestyle="--", color="w")
ax3.text(sample_means_200_25.mean() + 10, 0.004, "$\mu=%.2f$" % (sample_means_200_25.mean()), fontsize=12, rotation=90, color="m")
sns.histplot(sample_means_200_50, ax=ax4, color="y").set_title("Sample Means Distribution: 200 samples, $n = 50$")
ax4.axvline(facebook_friends.mean(), linestyle="-.", color="g")
ax4.axvline(sample_means_200_50.mean(), linestyle="--", color="w")
ax4.text(sample_means_200_50.mean() + 10, 0.004, "$\mu=%.2f$" % (sample_means_200_50.mean()), fontsize=12, rotation=90, color="y");
Facebook friends population parameters: $\mu =$ 205.49, $\sigma = $ 237.74
Sample means distributions
200 samples, $n = 5$
Theoretical: $\mathbf{E} = 205.49$ , $SE = \frac{\sigma}{\sqrt{n}} = \frac{237.74}{\sqrt{5}} = 106.32$
In practice: $\mathbf{E} = 208.30$ , $SE = 97.82$
200 samples, $n = 25$
Theoretical: $\mathbf{E} = 205.49$ , $SE = \frac{\sigma}{\sqrt{n}} = \frac{237.74}{\sqrt{25}} = 47.55$
In practice: $\mathbf{E} = 206.33$ , $SE = 49.45$
200 samples, $n = 50$
Theoretical: $\mathbf{E} = 205.49$ , $SE = \frac{\sigma}{\sqrt{n}} = \frac{237.74}{\sqrt{50}} = 33.62$
In practice: $\mathbf{E} = 202.31$ , $SE = 34.26$
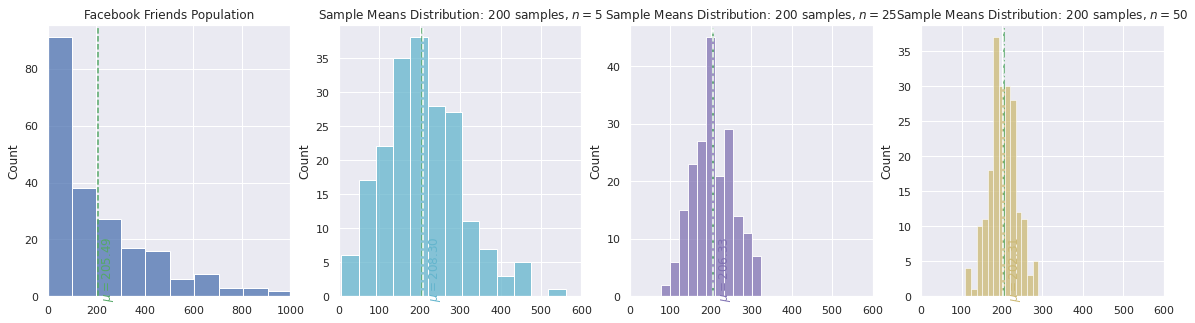
Notice that the Facebook friends population plot on the left is skewed to the right, positively skewed, since the majority of people have under 200 friends.
The other three density plots, moving from left to right, are sample mean distributions using 200 samples with a sample size of 5, 25 and 50, respectively. Notice how the distributions are approximately normal and the larger the sample size, the smaller the standard error and thus the spread of the distribution becomes narrower.



