
Instacart - Exploratory Analysis
In this notebook we will explore the Instacart data set made available on Kaggle in the Instacart Market Basket Analysis Competition. We will be using Python along with the Numpy, Pandas, and matplotlib libraries to load, explore, manipulate and visualize the data.
Support Functions
from IPython.display import Markdown, display
%matplotlib inline
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import scipy.stats
#----------------------------------------------------------------------
# Functions to load datasets into memory using space efficient data types.
def load_orders(path):
def convert_eval_set(value):
if 'prior' == value:
return np.uint8(1)
elif 'train' == value:
return np.uint8(2)
else:
return np.uint8(3) # 'test'
def convert_days_since_prior_order(value):
# 30 is the maximum value
if '' == value:
return np.int8(-1)
else:
return np.int8(np.float(value))
orders = pd.read_csv(path,
dtype={'order_id': np.uint32,
'user_id': np.uint32,
'order_number': np.uint8,
'order_dow': np.uint8,
'order_hour_of_day': np.uint8},
converters={'eval_set':convert_eval_set,
'days_since_prior_order':convert_days_since_prior_order})
orders = orders.astype({'eval_set': np.uint8,
'days_since_prior_order': np.int8})
return orders
def load_orders_prods(path):
return pd.read_csv(path, dtype={'order_id': np.uint32,
'product_id': np.uint32,
'add_to_cart_order': np.uint8,
'reordered': np.uint8})
def load_products(path):
return pd.read_csv(path, dtype={'product_id': np.uint16,
'aisle_id': np.uint8,
'department_id': np.uint8})
def load_aisles(path):
return pd.read_csv(path, dtype={'aisle_id': np.uint8})
def load_depts(path):
return pd.read_csv(path, dtype={'department_id': np.uint8})
#----------------------------------------------------------------------
# Functions to retrieve orders and products for a specific customer
def GetOrdersList(user_id, exclude_first_order=False):
print("Retrieving orders for user ID: {0}".format(user_id))
if exclude_first_order:
return orders[(orders.user_id == user_id) & (orders.eval_set == 'prior') & (orders.order_number > 1)].sort_values('order_number', ascending=True).order_id
else:
return orders[(orders.user_id == user_id) & (orders.eval_set == 'prior')].sort_values('order_number', ascending=True).order_id
def GetProductsForOrder(order_id, prior_orders=True):
if prior_orders:
return prior_prods[prior_prods.order_id == order_id]
else:
return last_prods[last_prods.order_id == order_id]
def GetProductsForAllOrdersByCust(user_id, unique_products_only=False, exclude_first_order=False):
orders_list = GetOrdersList(user_id, exclude_first_order)
if unique_products_only:
return prior_prods[prior_prods.order_id.isin(orders_list)].product_id.unique()
else:
return prior_prods[prior_prods.order_id.isin(orders_list)]
#----------------------------------------------------------------------
# Functions to plot common charts
def plot_scatter(ax, x, y, title, x_label, ylim=[], fit_Line=True):
if fit_Line:
fit = np.polyfit(x, y, deg=1)
ax.plot(x, fit[0] * x + fit[1], color='red')
ax.scatter(x,y,alpha=0.75);
ax.set_title(title)
ax.set_xlabel(x_label)
ax.grid(b=True, color='0.75', alpha=0.5)
if 1 == len(ylim):
ax.set_ylim(bottom=ylim[0])
elif 2 == len(ylim):
ax.set_ylim(ylim)
#----------------------------------------------------------------------
# Function to generate markdown output
# Ref: https://stackoverflow.com/a/32035217
def printmd(string):
display(Markdown(string))
Analysis of Customers and Orders
orders = load_orders('data/split/sf_train_set_orders.csv')
# Get list of user IDs.
customers = orders.user_id.unique()
customers_count = len(customers)
# List of orders in history
prior_orders_only = orders[(1 == orders.eval_set)]
final_orders_only = orders[(1 != orders.eval_set)]
orders_count = len(prior_orders_only.order_id)
overall_mean_orders_count = orders_count / customers_count
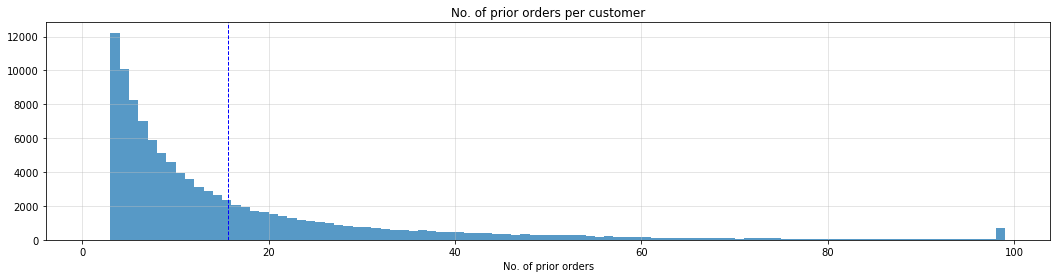
printmd("**{0:,}** customers with a mean order history of **{1:0.1f}** orders.".format(customers_count,
overall_mean_orders_count))
104,968 customers with a mean order history of 15.6 orders.
fig, ax = plt.subplots(1, 1, figsize=(18, 4))
count_of_orders_per_customer = prior_orders_only.groupby('user_id').order_id.count()
ax.hist(x=count_of_orders_per_customer,
bins=range(1, count_of_orders_per_customer.max()+1, 1),
alpha=0.75);
ax.set_title("No. of prior orders per customer")
ax.set_xlabel('No. of prior orders')
ax.grid(b=True, color='0.75', alpha=0.5)
ax.axvline(overall_mean_orders_count, color='b', linestyle='dashed', linewidth=1);
Detailed Analysis of Orders
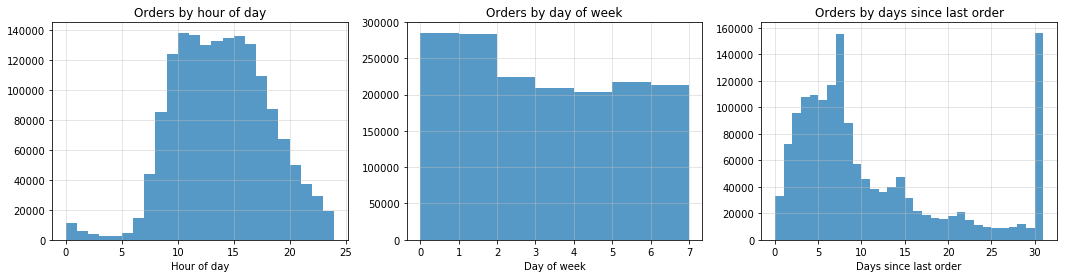
fig, ax = plt.subplots(1, 3, figsize=(18, 4))
ax = ax.ravel()
ax[0].hist(x=prior_orders_only.order_hour_of_day, bins=range(0, 25, 1), alpha=0.75);
ax[0].set_title("Orders by hour of day")
ax[0].set_xlabel('Hour of day')
ax[0].grid(b=True, color='0.75', alpha=0.5)
ax[1].hist(prior_orders_only.order_dow, bins=range(0, 8, 1), alpha=0.75);
ax[1].set_title("Orders by day of week")
ax[1].set_xlabel('Day of week')
ax[1].grid(b=True, color='0.75', alpha=0.5)
ax[2].hist(prior_orders_only[(prior_orders_only.order_number > 1)].days_since_prior_order, bins=range(0, 32, 1), alpha=0.75);
ax[2].set_title("Orders by days since last order")
ax[2].set_xlabel('Days since last order')
ax[2].grid(b=True, color='0.75', alpha=0.5)
Analysis of Days Since Last Order
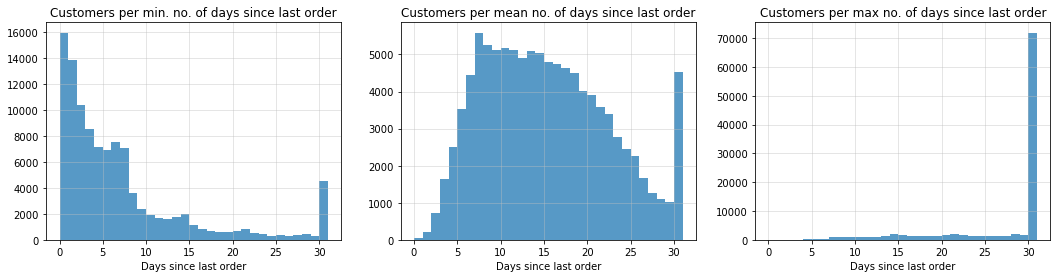
overall_mean_days_since_last_order = prior_orders_only[prior_orders_only.order_number > 1].days_since_prior_order.mean()
printmd("Mean no. of days since last order for all customers: **{0:0.1f}** days".format(overall_mean_days_since_last_order))
Mean no. of days since last order for all customers: 10.7 days
# DSLO - days since last order
min_DSLO_per_customer = prior_orders_only[prior_orders_only.order_number > 1].groupby('user_id').days_since_prior_order.min()
mean_DSLO_per_customer = prior_orders_only[prior_orders_only.order_number > 1].groupby('user_id').days_since_prior_order.mean()
max_DSLO_per_customer = prior_orders_only[prior_orders_only.order_number > 1].groupby('user_id').days_since_prior_order.max()
fig, ax = plt.subplots(1, 3, figsize=(18, 4))
ax = ax.ravel()
ax[0].hist(min_DSLO_per_customer, bins=range(0, 32, 1), alpha=0.75);
ax[0].set_title("Customers per min. no. of days since last order")
ax[0].set_xlabel('Days since last order')
ax[0].grid(b=True, color='0.75', alpha=0.5)
ax[1].hist(mean_DSLO_per_customer, bins=range(0, 32, 1), alpha=0.75);
ax[1].set_title("Customers per mean no. of days since last order")
ax[1].set_xlabel('Days since last order')
ax[1].grid(b=True, color='0.75', alpha=0.5)
ax[2].hist(max_DSLO_per_customer, bins=range(0, 32, 1), alpha=0.75);
ax[2].set_title("Customers per max no. of days since last order")
ax[2].set_xlabel('Days since last order')
ax[2].grid(b=True, color='0.75', alpha=0.5)
Analysis of Ordered Products
orders_prods = load_orders_prods('data/split/sf_train_set_prior_order_products.csv')
orders_length = orders_prods.groupby('order_id').add_to_cart_order.max()
orders_length = orders_length.reset_index()
orders_length.rename(columns={'add_to_cart_order': 'total_items_ordered'}, inplace=True)
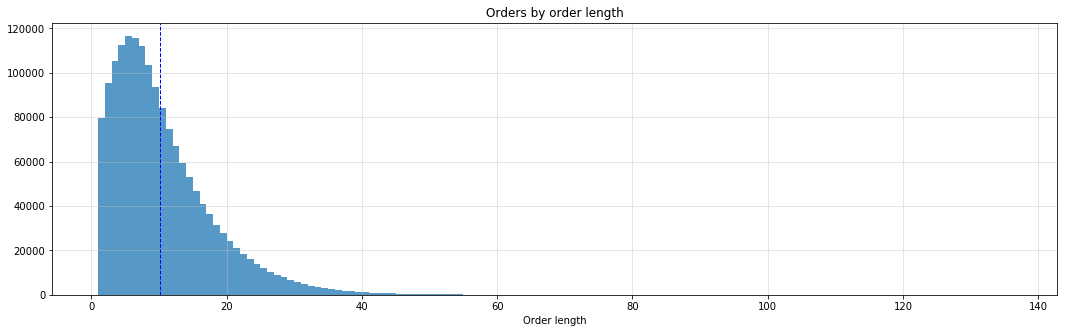
overall_mean_order_length = orders_length.total_items_ordered.mean()
printmd("Overall mean no. of items ordered per order: **{0:0.1f}** items".format(overall_mean_order_length))
Overall mean no. of items ordered per order: 10.1 items
fig, ax = plt.subplots(1, 1, figsize=(18, 5))
ax.hist(orders_length.total_items_ordered, bins=range(1, orders_length.total_items_ordered.max(), 1), alpha=0.75);
ax.set_title("Orders by order length")
ax.set_xlabel('Order length')
ax.grid(b=True, color='0.75', alpha=0.5)
ax.axvline(overall_mean_order_length, color='b', linestyle='dashed', linewidth=1);
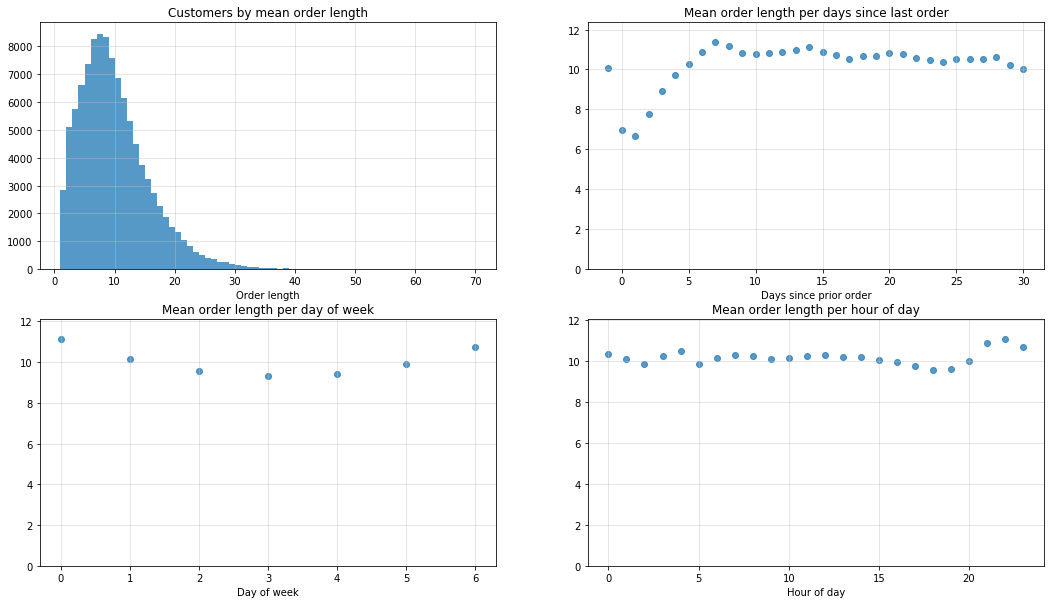
orders_length_merge = pd.merge(orders_length, prior_orders_only, on='order_id')
orders_length_merge['order_id'] = orders_length_merge.order_id.astype(np.uint32)
mean_order_length_per_customer = orders_length_merge.groupby('user_id').total_items_ordered.mean().reset_index()
mean_order_length_per_DSLO = orders_length_merge.groupby('days_since_prior_order').total_items_ordered.mean().reset_index()
mean_order_length_per_DoW = orders_length_merge.groupby('order_dow').total_items_ordered.mean().reset_index()
mean_order_length_per_Hour = orders_length_merge.groupby('order_hour_of_day').total_items_ordered.mean().reset_index()
fig, ax = plt.subplots(2, 2, figsize=(18, 10))
ax = ax.ravel()
ax[0].hist(mean_order_length_per_customer.total_items_ordered,
bins=range(1, np.uint32(np.ceil(mean_order_length_per_customer.total_items_ordered.max())), 1), alpha=0.75);
ax[0].set_title("Customers by mean order length")
ax[0].set_xlabel('Order length')
ax[0].grid(b=True, color='0.75', alpha=0.5)
plot_scatter(ax[1],
mean_order_length_per_DSLO.days_since_prior_order,
mean_order_length_per_DSLO.total_items_ordered,
'Mean order length per days since last order',
'Days since prior order',
ylim=[0,mean_order_length_per_DSLO.total_items_ordered.max()+1],
fit_Line=False)
plot_scatter(ax[2],
mean_order_length_per_DoW.order_dow,
mean_order_length_per_DoW.total_items_ordered,
'Mean order length per day of week',
'Day of week',
ylim=[0,mean_order_length_per_DoW.total_items_ordered.max()+1],
fit_Line=False)
plot_scatter(ax[3],
mean_order_length_per_Hour.order_hour_of_day,
mean_order_length_per_Hour.total_items_ordered,
'Mean order length per hour of day',
'Hour of day',
ylim=[0, mean_order_length_per_Hour.total_items_ordered.max()+1],
fit_Line=False)
Analysis of Reordered Products
# For each order compute ratio of re-ordered items to total ordered items.
orders_reorder_ratio = orders_prods.groupby('order_id').reordered.sum() / orders_length.set_index('order_id').total_items_ordered
# Exclude first orders, since none of the products have been ordered yet,
# and so reordered ratio would be zero, thus skewing the mean reorder ratio
# both overall and per user.
orders_reorder_ratio = pd.merge(orders_reorder_ratio.reset_index(), prior_orders_only[prior_orders_only.order_number > 1], on='order_id')
orders_reorder_ratio.rename(columns={0: 'reorder_ratio'}, inplace=True)
orders_reorder_ratio['order_id'] = orders_reorder_ratio.order_id.astype(np.uint32)
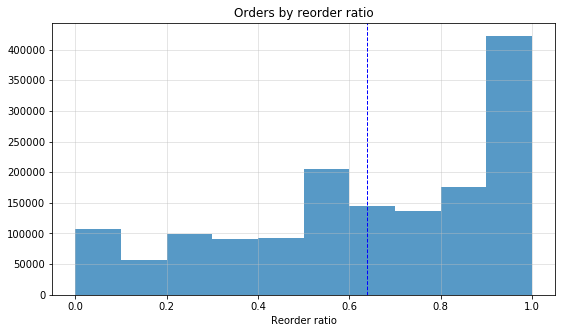
overall_mean_reorder_ratio = orders_reorder_ratio.reorder_ratio.mean()
printmd("Overall mean reorder ratio: **{0:0.2f}**".format(overall_mean_reorder_ratio))
Overall mean reorder ratio: 0.64
fig, ax = plt.subplots(1, 1, figsize=(9, 5))
ax.hist(orders_reorder_ratio.reorder_ratio, alpha=0.75);
ax.set_title("Orders by reorder ratio")
ax.set_xlabel('Reorder ratio')
ax.grid(b=True, color='0.75', alpha=0.5)
ax.axvline(overall_mean_reorder_ratio, color='b', linestyle='dashed', linewidth=1);
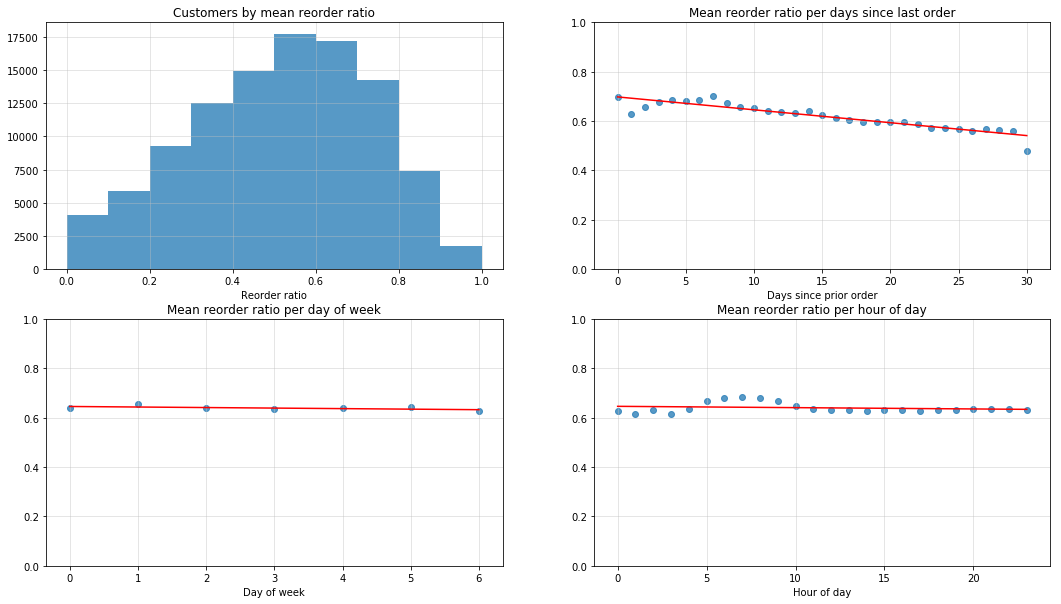
mean_reorder_ratio_per_user = orders_reorder_ratio.groupby('user_id').reorder_ratio.mean().reset_index()
mean_reorder_ratio_per_DSLO = orders_reorder_ratio.groupby('days_since_prior_order').reorder_ratio.mean().reset_index()
mean_reorder_ratio_per_DoW = orders_reorder_ratio.groupby('order_dow').reorder_ratio.mean().reset_index()
mean_reorder_ratio_per_Hour = orders_reorder_ratio.groupby('order_hour_of_day').reorder_ratio.mean().reset_index()
fig, ax = plt.subplots(2, 2, figsize=(18, 10))
ax = ax.ravel()
ax[0].hist(mean_reorder_ratio_per_user.reorder_ratio, alpha=0.75);
ax[0].set_title("Customers by mean reorder ratio")
ax[0].set_xlabel('Reorder ratio')
ax[0].grid(b=True, color='0.75', alpha=0.5)
plot_scatter(ax[1],
mean_reorder_ratio_per_DSLO.days_since_prior_order,
mean_reorder_ratio_per_DSLO.reorder_ratio,
'Mean reorder ratio per days since last order',
'Days since prior order',
ylim=[0,1])
plot_scatter(ax[2],
mean_reorder_ratio_per_DoW.order_dow,
mean_reorder_ratio_per_DoW.reorder_ratio,
'Mean reorder ratio per day of week',
'Day of week',
ylim=[0,1])
plot_scatter(ax[3],
mean_reorder_ratio_per_Hour.order_hour_of_day,
mean_reorder_ratio_per_Hour.reorder_ratio,
'Mean reorder ratio per hour of day',
'Hour of day',
ylim=[0,1])
Analysis of Products
products = load_products('data/original/products.csv')
aisles = load_aisles('data/original/aisles.csv')
depts = load_depts('data/original/departments.csv')
Count of Unique Products Purchased
count_diff_products_ordered = len(orders_prods.product_id.unique())
printmd("Different products ordered: **{0}**".format(count_diff_products_ordered))
Different products ordered: 49188
Overall Product Probabilities
# Laplace smoothing to assign some prob. to products ordered only once.
overall_product_probabilities = orders_prods.groupby('product_id').reordered.sum() + 1
overall_product_probabilities = overall_product_probabilities / overall_product_probabilities.sum()
overall_product_probabilities.sort_values(inplace=True, ascending=False)
overall_product_probabilities = overall_product_probabilities.reset_index()
printmd("**Top 20 products ordered with probabilities.**<br/>")
print("{0:30} {1}".format("Product", "Probability"))
print("-------------------------------------------")
for prod, prob in list(zip([products[products.product_id == p].product_name.item() for p in overall_product_probabilities[:20].product_id],
[p for p in overall_product_probabilities[:20].reordered])):
print("{0:30} {1:0.4f}".format(prod, prob))
Top 20 products ordered with probabilities.
Product Probability
-------------------------------------------
Banana 0.0207
Bag of Organic Bananas 0.0163
Organic Strawberries 0.0108
Organic Baby Spinach 0.0097
Organic Hass Avocado 0.0088
Organic Avocado 0.0070
Organic Whole Milk 0.0060
Large Lemon 0.0055
Organic Raspberries 0.0055
Strawberries 0.0051
Limes 0.0050
Organic Yellow Onion 0.0041
Organic Garlic 0.0039
Organic Zucchini 0.0037
Cucumber Kirby 0.0035
Organic Fuji Apple 0.0033
Apple Honeycrisp Organic 0.0033
Organic Blueberries 0.0033
Organic Lemon 0.0032
Organic Half & Half 0.0032



